
![]()
Recursive Logistic Equation
Background:The logistic equation kx(1-x) normally is used for things like population dynamics. The input to the
equation would run from 0-1 in increments of 0.1 for our example. In this way we have normalized our equation to keep things simple.
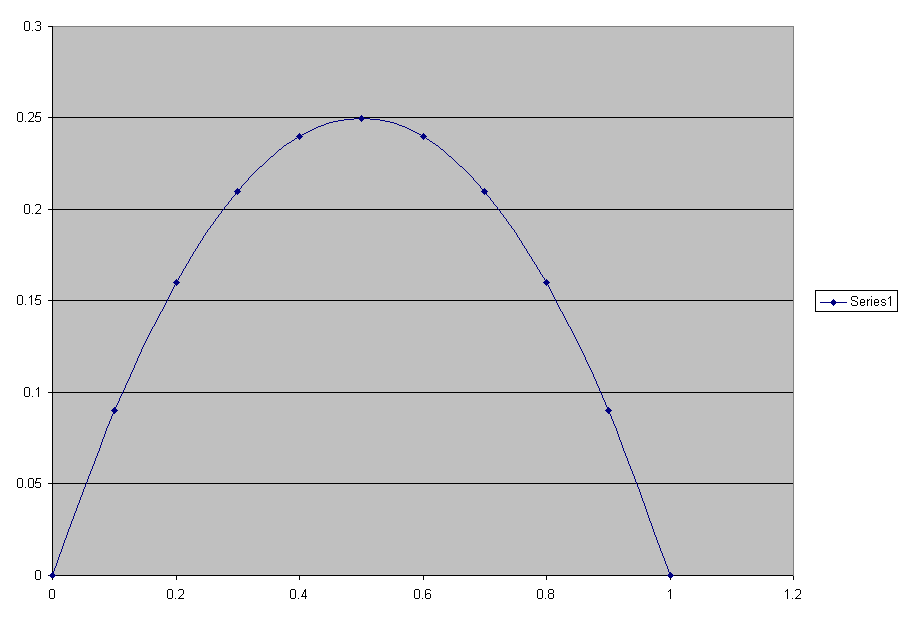
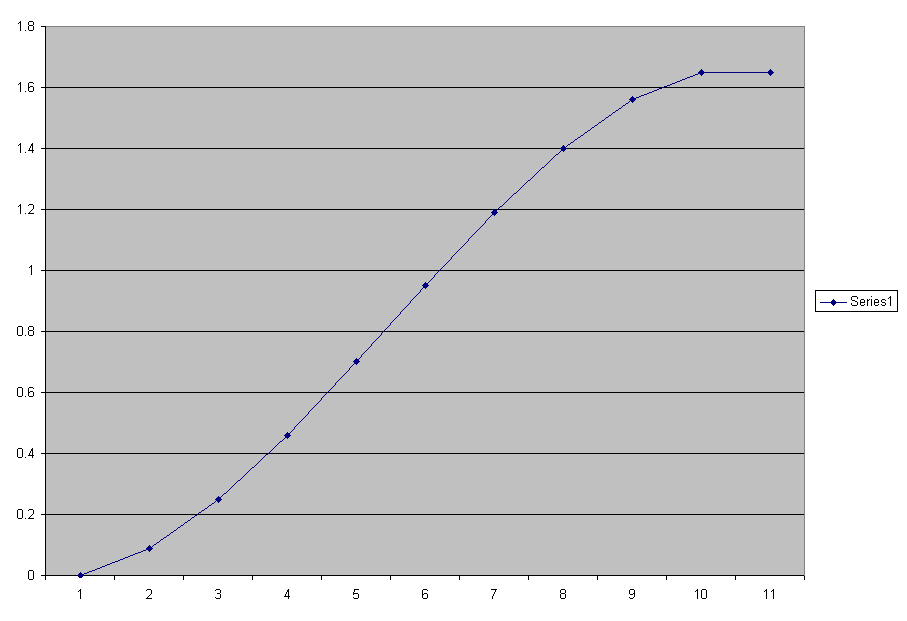
Below lets set k to 1 so the equation becomes y = x(1-x). Sum(Y) is the sum of the Y's as we move down. Sum(Y) could represent
a population. As you can see with the logistic equation Y at first increases because the population is small and the resources
available are large for it (bacteria, animals, products in a market... so on). For bacteria it could mean that the food source in the Petri dish
is the limit. For products it could mean nobody has gadget X at this time. So the bacteria mutiply or products get sold at what seems like
an ever increasing rate initially until Y climbs to 0.25. Then the limits of the environment kick in and the population growth slows down
to 0 when X = 1. The population curve is an S shaped curve where the population starts growing slowly, then increases fairly linear in the
middle section and then approaches level at saturation as enviromental constaints apply a final limit on sustainability. This applies to the
Bacterial culture in the Petri dish or Yogurt, products in a market and even the yeast colony fermenting sugar to alcohol in beer and winemaking.
X Y Sum(Y)
0 0 0
0.1 0.09 0.09
0.2 0.16 0.25
0.3 0.21 0.46
0.4 0.24 0.7
0.5 0.25 0.95
0.6 0.24 1.19
0.7 0.21 1.4
0.8 0.16 1.56
0.9 0.09 1.65
1 0 1.65
Plot of X and Y.
Plot of Sum(Y).
It is a pretty tame looking thing, this equation and the curves that it generates, that is until we use feedback. Once we start feeding the output of kx(1-x) into itself repeatedly interesting things happen for different values of k. Recursive feedback makes things more interesting, that is where we are going next...
Now the main story:The recursive logistic equation provides some unique insight into how chaos can emerge from simple math. kx(1-x) is the innocent looking equation. Who would ever expect chaotic behavior from it. But take it and keep feeding its result back into itself and you get interesting behavior for various values of k. Use the x = kx[n-1](1-x[n-1]) in a program and you get the following results for various regions of k.
Bifurcations occur when the oscillations split from 1 to 2 to 4 and so on until there are many separate superimposed oscillations. This is similar to a water faucet dripping. A first it is just a single drip period, increase the rate and then it drips at beats that are superimposed periods, finally it becomes a chaotic flow. This is the basic behavior of when laminar flow such as slow rising smoke from cigarettes or inscence breaks into a turbulent mass of rolling smoke. There is a point where it goes from laminar to turbulent much like the recursive logistic equation goes unstable right around k = 3.57.
After k = 3.57 it goes down right chaotic, not just too many oscillations to read that are superimposed. At k = 4 it is a random number generator. Above k = 4 it just exponentially goes off of the deep end, the equation blows up into large numbers very quickly, even for small values over such as k = 4.00001.
The point is that it does not take complex math to generate complex behavior, this example shows this plainly. Other examples of this behavior include cellular automata and Turing machines. Good information on cellular automata exists in the book A New Kind of Science by Steven Wolfram.
See the excel plots link below to see the behavior of the recursive logistic equation for various k. This just touches the tip on what is out there on the logistic equation, which originated to study the behavior of wildlife populations.
Behavior of the equation for regions of k
Zones of k
0-.999 Convergance to 0.
1-1.999 1st order like,convergence to a constant.
2-2.999… 2nd order like, convergence to a constant
2-2.2 overshoot
2.2-2.4 over/undershoot
2.4-2.999… Damped oscillation that dies off to a constant.
3.0-3.999 Oscillations that do not damp.( Actually it seems that oscillations do not damp for values that start slightly above 3.0 like 3.05.)
3.0-3.3 Seems to become multi-oscillatory(modulated) at 3.3
3.4-3.56 Bifurcations, over and over.
3.57-4.0 Chaotic,unstable.
4.0 Pseudorandom number generator, seeded with initial value i.
-> 4.0 Unbound growth, reaches a point where it will go negative
exponentially until it produces a math underflow.
Dependance on constant k and initial condition i
It is interesting to look at the behavior of the recursive logistic equation response to varying both what is referred to as k the multiplication
constant and what is referred to as i. The term i refers to the initial seed value that is put into the equation. This initial condition of
the seed value can vary from 0 to 1. The cases 0 and 1 are not interesting so we will narrow the study down to the range 0.1 to 0.9 in steps of 0.1.
The value k will be varied from 1 to 4 with steps of 0.5.
The first set of data shows the average of the output over 64 iterations. For k <= 2.8 the function tends to settle to a constant steady
state value. Above this range but below about k = 3.0 the function is a damped oscillation. However it is becoming more and more
strongly influenced by i the initial condition. Values of i near the value of the long term average tend to drive the system and
cause it to oscillate longer for lower values of k(larger than 2.0), or supply enough 'energy' to force the function into continuous oscillation for the case where k is around 3.01 - 3.05.
As a matter of fact for k = 3.01, using 0.66 for i shows an output where oscillations build. When numbers such as 0.1 or 0.8 as used for
i the oscillations dies off to a lower steady state. For values of i such as 0.7 the oscillations start off and remain at a steady
amplitude. It appears that for k in the region near 3.01 there is a high sensitivity developing for the initial conditions. For k = 3.0
the best that can be achieved is a steady oscillation amplitude for an i that is close to the average value (0.66), values away from this produce a
decaying oscillation.
avg 64
(k) 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
(i)
1 0.030999 0.040047 0.045142 0.048408 0.050485 0.051533 0.051392 0.049422 0.043499
1.5 0.319383 0.327675 0.332218 0.335166 0.337138 0.338291 0.338468 0.337050 0.331883
2 0.484013 0.491354075 0.495419877 0.49811248 0.5 0.50123748 0.501669877 0.500729075 0.496513183
2.5 0.583910 0.590625 0.59436468 0.596875 0.598674985 0.6 0.60061468 0.6 0.596410396
3 0.648893 0.653819074 0.659351342 0.661078842 0.661813413 0.664203842 0.665601342 0.663194074 0.661392638
3.5 0.634356 0.637031415 0.648897153 0.646341886 0.646396698 0.649466886 0.655147153 0.646406415 0.646856094
4 0.473525 0.479462944 0.539980301 0.496441489 0.0234375 0.499566489 0.546230301 0.466972349 0.468859493
The following data show the output value for iterations 5 and 6 (t = 5,t = 6) for various k and i. What can be seen is that some
combinations will settle down quickly in value and others will not. For low values of k there is a settling to steady state, for medium values
there is oscillatory behavior that settles to a steady state. For high values there is oscillatory and chaotic behavior in which the swing between the
output at t = 5 and 6 can be a wide range apart.
Particularly noteworthy is the fact that at the higher values of k the behavior at an early time in the response of the system , it's transient
response is determined heavily by the initial condition i. For k < 3 the system settles down to its final value quickly.
t =5
(k) 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
(i)
1 0.064703 0.092234087 0.105013402 0.110789235 0.11245925 0.110789235 0.105013402 0.092234087 0.064702892
1.5 0.284690 0.323030 0.332061 0.334771 0.335405 0.334771 0.332061 0.323030 0.284690
2 0.499604 0.49999996 0.5 0.5 0.5 0.5 0.5 0.49999996 0.499603859
2.5 0.603800 0.6 0.596847682 0.6 0.601659149 0.6 0.596847682 0.6 0.603800036
3 0.721109 0.580641291 0.631621878 0.714574615 0.73095992 0.714574615 0.631621878 0.580641291 0.721108834
3.5 0.561396 0.446471551 0.80695487 0.833286159 0.87499718 0.833286159 0.80695487 0.446471551 0.561395981
4 0.585421 0.585420539 0.087945365 0.006407737 0 0.006407737 0.087945365 0.585420539 0.585420539
t=6
(k) 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
(i)
1 0.060516 0.08372696 0.093985588 0.09851498 0.099812167 0.09851498 0.093985588 0.08372696 0.060516428
1.5 0.305462 0.328022297 0.332694877 0.334049283 0.334362862 0.334049283 0.332694877 0.328022297 0.305462355
2 0.500000 0.5 0.5 0.5 0.5 0.5 0.5 0.5 0.499999686
2.5 0.598064 0.6 0.601551316 0.6 0.599163544 0.6 0.601551316 0.6 0.598063881
3 0.603333 0.730490947 0.698027044 0.611873204 0.589972547 0.611873204 0.698027044 0.730490947 0.603332651
3.5 0.861807 0.864971468 0.545225478 0.486221177 0.382819904 0.486221177 0.545225478 0.864971468 0.861806867
4 0.970813 0.970813326 0.32084391 0.025466713 0 0.025466713 0.32084391 0.970813326 0.970813326
This last grouping of the data is the difference between the output at t=5 and t=6. Clearly for the higher values of k the function output
has wide variations. Where as for lower values of k the output of the function has by t = 5 & 6 settled down to its final value.
For k = 4 what we have is a pseudorandom number generator where i is the initial seed value. The only problem is that i = 0.5
is an invalid case and will cause it not to run. Also if the output ever reaches 0.5 the function will halt on zero as well.
delta
k 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
(i)
1 -0.004186 -0.008507 -0.011028 -0.012274 -0.012647 -0.012274 -0.011028 -0.008507 -0.004186
1.5 0.020772 0.004993 0.000634 -0.000722 -0.001042 -0.000722 0.000634 0.004993 0.020772
2 0.000396 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000396
2.5 -0.005736 0.000000 0.004704 0.000000 -0.002496 0.000000 0.004704 0.000000 -0.005736
3 -0.117776 0.149850 0.066405 -0.102701 -0.140987 -0.102701 0.066405 0.149850 -0.117776
3.5 0.300411 0.418500 -0.261729 -0.347065 -0.492177 -0.347065 -0.261729 0.418500 0.300411
4 0.385393 0.385393 0.232899 0.019059 0.000000 0.019059 0.232899 0.385393 0.385393
Correlation:Separating Randomness From Deterministic Chaos
Chaos is deterministic. The simple logistic equation can be used as a random number generator, however the output is not random. It is deterministic
chaos. What looks random to the naked eye can sometimes have underlying chaos. In some cases this is easy to prove. Remember above where iteration
5 and 6 are shown. What if we plotted all the output values in such a way to accentuate the differences between each output step. The way to do this is to use correlation. By plotting the output values in such a way that the outputs at (T) are plotted on the X axis and (T+1) are plotted on the Y axis
the underlying chaos will reveal itself in the pattern that appears.
For example the following data shows the output from the recursive logistic equation for k=4 and i = 0.4 set up to show what values would be
plotted on each axis.
X Y
0.4 0.96
0.96 0.1536
0.1536 0.52002816
0.52002816 0.998395491
0.998395491 0.006407737
0.006407737 0.025466713
0.025466713 0.099272637
0.099272637 0.357670323
0.357670323 0.918969052
0.918969052 0.297859733
The following first plot shows an XY plot for the above values plus another 40, for a total of 50 points. The curve is a parabola, clearing showing deterministic chaos. If the process were truly random each point should be uncorrelated and the plot should be a random scatter. The second plot shows a truly random scatter of 50 values in the XY plane.
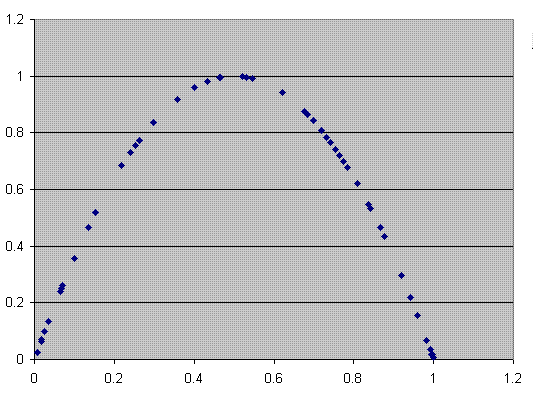
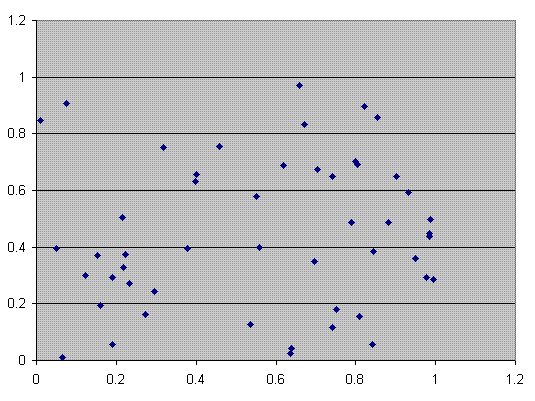
Of course in real life I would't expect things to be as simple as this example. Some systems like the stock market or the weather might have some
deterministic patterns to them that are hard to pick out for the following two (or a combination of both) reasons.
1. There may be a lot of randomness that hides the patterns. The so called signal that we are looking for is near or under the noise floor.
2. There may be so many overlapping deterministic chaotic processes working that the XY plot is too complex to pick out a pattern. Too many signals occupying
the same space.
To summarize. Chaotic processes are not random and it is possible to pick out patterns that separate the two. This can be extended from our simple
example to a problem in n dimensions as well. The key here is by shifting the problem from something in the time domain into a correlation domain,
revealing a pattern. See also Complexification - John L. Casti - Harper Perennial
Sometimes this is the key to revealing a pattern, shifting from one domain to another mathematically can help find it.
Shifting from a time domain view to a frequency domain (via Fourier transform) view can be helpful as well, with certain analysis.
Another type of XY analysis commonly used in electrical engineering is to plot the input of a system on the X axis and the output on the Y axis. This is
what would be called a linearity and phase plot. If the system is linear and has no phase shift a line at a 45 degree angle will result.
Nonlinearity will show up as a bend in the line, phase shift will cause the plot to open up. This will result in a circle at a 90 degree phase shift and more complicated lissajous figures for higher phase shifts.
This method could be used as well to reveal sensitivity on input changes. By shifting the input conditions around slightly and seeing how far
the outputs change on the XY plot.
The idea is to generate a base line case XY plot and then vary the input that generates X, plotting that as new Y graphs.
This would show a family of curves that shows how sensitive the system is to small changes in input. If it is not sensitive the lines will overlap, if it
is sensitive the lines will change position and shape away from the baseline quickly. If there is sensitive dependance on
input conditions, the output will show a large spread in the resulting plot.
My Additional Random Thoughts
Another interesting idea related to chaos is the fact of what time and location the randomness gets into the system to begin with. Is it when a die finally lands on its number or is it when it leaves the throwers hand? It is actually closer to when it leaves the hand, the initial conditions, from this point the so called butterfly effect kicks in. So it is almost moot to yell at the die come on 6, come on 6 or what ever.
Related, the observation of outcome occurs when the first observer, human or instrument actually observes. When the die lands finally in its resting place, in essence its wave function collapses to an observable state. It is interesting to extrapolate this to the famous Schrödinger's Cat experiment. This idea of the fact that whatever instrument that actually interacts macroscopically with the radioactive particle that leads to the demise of the cat is the actually observer. It is the interface between quantum and macroscopic that the observation occurs, much like throwing a die that finally comes to halt on a stable (point) attractor, the line where chaos becomes static stability.
![]()
Original Build Date:07-18-2005
Last updated 12-23-2007